Charsets et encoding
( Cet article est la traduction française de http://sebsauvage.net/python/snyppets/index.html#unicode )
Si vous pensez que texte = ASCII = 8 bits = 1 octet par caractère, vous avez tout faux.
C'est une façon de voir très étriquée.
Il y a quelquechose que tout développeur devrait savoir, sans quoi il se prendra forcément les pieds dedans un jour ou l'autre:
Charsets et encoding
(Jeux de caractères et encodage)
Ok, laissez-moi mettre les points sur les i:
Vous savez que l'ordinateur est une grosse machine stupide. Elle ne connaît rien des alphabets ni même des nombres décimaux. Un ordinateur est une machine à manipuler des bits.
Donc quand nous avons des symboles tels que la lettre 'a' ou le point d'interrogation '?', nous devons trouver une représentation binaire de ces symboles pour l'ordinateur.
C'est le seul et unique moyen de les stocker dans la mémoire de l'ordinateur.
Les jeux de caractères (charset)
Tout d'abord, nous devons choisir quel nombre utiliser pour représenter chaque symbole. C'est une bête table de la forme:
Symbole → Nombre
ASCII vient immédiatement à l'esprit.
En ASCII, la lettre 'a' correspond au nombre 97. Le point d'interrogation '?' au nombre 67.
Mais ASCII est loin d'être un standard universel.
Il y a des tas de jeux de caractères tels que EBCDIC, KOI8-R pour les caractères cyrilliques (Russes), ISO-8852-1 pour les caractères latins (caractères accentués, par exemple), Big5 for pour le Chinois traditionnel, Shift_JIS pour le Japonais, etc. Chaque pays, culture, langue a développé son propre jeu de caractères. C'est un bordel pas possible.
Un effort international tente de standardiser tout ça: UNICODE.
Unicode est une énorme table qui dit quel nombre utiliser pour chaque symbole.
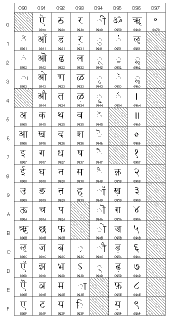
Quelques exemples:
 |
 |
 |
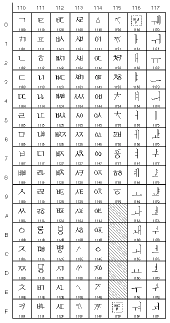 |
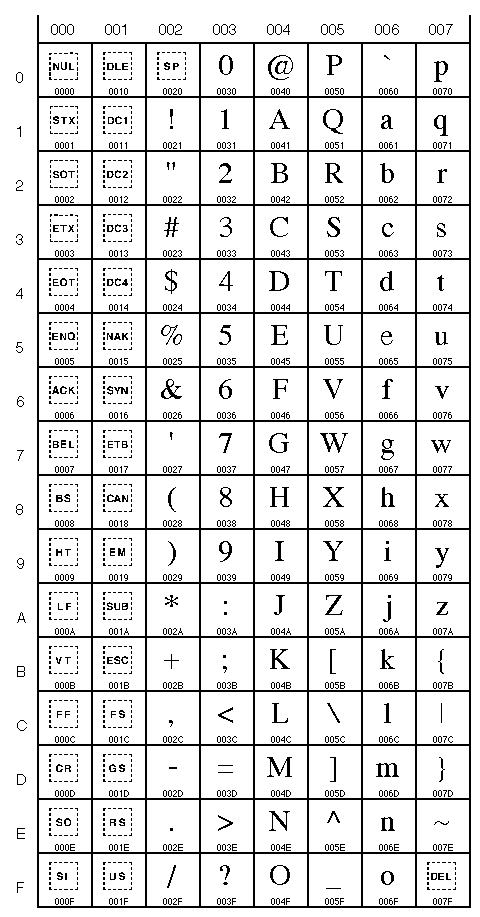
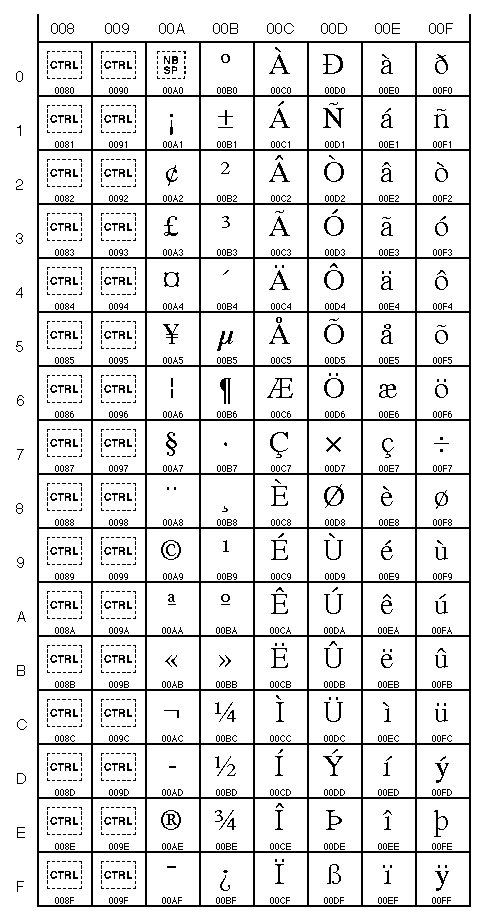
Table Unicode
0000 à 007F (0 à 127)
(Caractères latins) |
Table Unicode
0080 à 00FF (128 à 255)
(Caractères latins,
y compris les
caractères accentués) |
Table Unicode
0900 à 097F (2304 à 2431)
(devanagari) |
Table Unicode
1100 à 117F (4352 à 4479)
(hangul jamo) |
Donc le mot "bébé" donne les nombres suivants: 98 233 98 233 (ou 0062 00E9 0062 00E9 en hexadécimal 16 bits).
L'encodage (encoding)
Maintenant que nous avons tous ces nombres, nous devons leur trouver une représentation binaire.
Nombres → Bits
L'ASCII utilise une correspondance simple: 1 code ASCII (0...127) = 1 octet (8 ou 7 bits). C'est suffisant pour l'ASCII, parceque l'ASCII utilise seulement les nombres 0 à 127. Ça tient dans un octet.
Mais pour l'Unicode et les autres jeux de caractères, ça pose problème: 8 bits ne suffisent pas. Ces jeux de caractères nécessitent d'autres encodages.
La plupart utilisent des encodages multi-octets (un caractères est représenté par plusieurs octets).
Pour l'Unicode, il y a plusieurs encodages. Le premier est l'encodage brut en 16 bits, soit 16 bits (2 octets) par caractère.
Mais comme la plupart des textes utilisent seulement la partie basse de la table Unicode (0 à 127), c'est un énorme gaspillage de place.
C'est pour cela que l'UTF-8 a été inventé.
C'est génial:
Pour les codes 0 à 127, on utilise simplement 1 octet par caractère, comme pour l'ASCII.
Si vous avez besoin de caractères spéciaux (moins courants, codes 128 à 2047), utilisez 2 octets.
Si vous avez besoin de caractères spéciaux encore moins courants (codes 2048 à 65535), utilisez 3 octets.
et ainsi de suite.
Valeur Unicode
(en hexadécimal) |
Encodage en bits |
| 00000000 à 0000007F |
0xxxxxxx |
| 00000080 à 000007FF |
110xxxxx 10xxxxxx |
| 00000800 à 0000FFFF |
1110xxxx 10xxxxxx 10xxxxxx |
| 00010000 à 001FFFFF |
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
| 00200000 à 03FFFFFF |
111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
| 04000000 à 7FFFFFFF |
1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx |
Du coup, pour la plupart des textes latins, c'est aussi efficace que l'ASCII (1 octet par caractère), mais cela vous laisse la possibilité d'utiliser n'importe quel caractère Unicode.
Pas mal, non ?
Résumons !
| Symbole |
→ |
Nombre |
→ |
Bits |
|
charset
(jeu de
caractères) |
|
encoding
(encodage) |
|
Le charset vous dira quel nombre utiliser pour chaque symbole.
L'encoding vous dira comment encoder ces nombres sous forme de bits.
Un exemple simple:
| é |
→ |
233 |
→ |
C3 A9 |
|
|
en Unicode |
|
en UTF-8 |
Donc pour le mot "bébé":
| bébé |
→ |
98 233 98 233 |
→ |
62 C3 A9 62 C3 A9 |
|
|
en Unicode |
|
en UTF-8 |
Si je reçois les octets 62 C3 A9 62 C3 A9 sans la connaissance de l'encodage et du charset utilisés, ces octets ne me seront d'aucune utilité.
La plupart des programmeurs naïf afficheront ces octets tel quel: 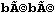
et demanderont "Mais pourquoi j'ai ces caractères bizarres ?"
Maintenant que vous avez lu cet article, vous ne ferez plus cette erreur.
Transmettre un texte seul est inutile.
Quand vous transmettez un texte, vous devez toujours aussi transmettre quel charset/encoding vous avez utilisé.
C'est aussi la raison pour laquelle un certain nombre de pages web sont foireuses: Elles n'indiquent pas le charset et l'encodage.
Savez-vous que dans ce cas votre navigateur essai de deviner le charset ?
C'est mal.
Toute page web devrait indiquer son charset/encodage dans les entêtes HTTP, ou à défaut dans le corps du fichier HTML (dans le <head>). Exemple:
<meta http-equiv="Content-Type" content="text/html; charset=iso-8859-1">
C'est la même chose pour les emails: N'importe quel logiciel d'email digne de ce nom indique quel charset/encodage est utilisé dans le corps du mail (ces informations sont indiquées dans les entêtes SMTP du mail (RFC 822)).
Astuce: Certains encodage sont spécifiques à certains charsets. Par exemple, l'encodage UTF-8 n'est utilisé que pour l'Unicode. Donc si vous recevez de l'UTF-8, vous savez que c'est de l'Unicode.
La suite de cet article concerne le langage de programmation Python - Vous pouvez ignorer la suite si vous ne programmez pas en Python.
Python et Unicode
Python supporte directement Unicode et UTF-8.
Utilisez-les autant que possible.
Votre programme supportera sans difficulté les caractères internationaux.
Tout d'abord, vous devriez toujours indiquer dans quel charset/encoding votre source Python est écrit. Pour cela, indiquez-le au début du fichier:
#!/usr/bin/python
# -*- coding: iso-8859-1 -*-
Ensuite, utilisez des chaînes Unicode dans vos programmes (utilisez le préfixe 'u'):
mauvaiseChaine = "Mauvaise chaine !"
bonneChaine = u"Bonne chaine Unicode."
autreBonneChaine = u"Ma vie, mon \u0153uvre."
( \u0153 est le caractère unicode "œ" (0153 est le code pour "œ"). Le caractère "œ" est dans la section latin-1 des tables: http://www.unicode.org/charts/ )
Pour convertir une chaîne standard en Unicode, faites:
maChaineUnicode = unicode(uneChaine)
ou
maChaineUnicode = uneChaine.decode('iso-8859-1')
Pour convertir une chaîne Unicode dans un charset spécifique, faites:
uneChaine = maChaineUnicode.encode('iso-8859-1')
La liste des charsets/encodings supportés par Python est disponible là: http://docs.python.org/lib/standard-encodings.html
N'oubliez pas que quand vous faites un print, vous utilisez le charset de la console (stdout). Donc parfois, afficher une chaîne Unicode peut échouer, parceque votre chaîne peut très bien contenir des caractères Unicode qui n'ont pas d'équivalents dans le charset du terminal de votre système d'exploitation.
Je vais le répéter encore une fois: Une simple instruction print peut échouer.
Exemple, avec le mot "œuvre":
>>> a = u'\u0153uvre'
>>> print a
Traceback (most recent call last):
File "<stdin>", line 1, in ?
File "c:\python24\lib\encodings\cp437.py", line 18, in encode
return codecs.charmap_encode(input,errors,encoding_map)
UnicodeEncodeError: 'charmap' codec can't encode character u'\u0153' in position 0: character maps to <undefined>
Ce que Python est en train de vous dire, c'est que le caractère Unicode 153 (œ) n'a pas d'équivalent dans le jeu de caractères qu'utilise la console de votre système d'exploitation.
Pour savoir quel charset votre console utilise, faites:
>>> import sys
>>> print sys.stdout.encoding
cp437
Donc pour être sûr d'afficher sans erreur, vous pouvez faire:
>>> import sys
>>> a = u'\u0153uvre'
>>> print a.encode(sys.stdout.encoding,'replace')
?uvre
>>>
Les caractères Unicode qui ne peuvent pas être affichés seront remplacés par '?'.
Note importante: Quand vous travailler avec des sources de données externes (fichiers, bases de données, stdin/stdout/stderr, des API, COM sous Windows, la base de registre...) soyez prudent: La plupart ne communiquent pas en Unicode, mais dans un charset précis. Vous devez convertir depuis et vers Unicode en fonction.
Par exemple, pour écrire une chaîne Unicode dans un fichier encodé en UTF-8, vous pouvez faire:
>>> a = u'\u0153uvre'
>>> file = open('monfichier.txt','w')
>>> file.write( a.encode('utf-8') )
>>> file.close()
Pour lire ce même fichier:
>>> file = open('monfichier.txt','r')
>>> print file.read()
œuvre
>>>
Oups... Il y a un problème. Nous avons ouvert le fichier, mais nous n'avons pas spécifié l'encodage lors de la lecture. D'où les caractères bizarres "┼ô" (Ce sont des codes UTF-8). Décodons l'UTF-8:
>>> file=open('monfichier.txt','r')
>>> print repr( file.read().decode('utf-8') )
u'\u0153uvre'
>>>
C'est bon. C'est bien notre mot "œuvre".
Vous vous souvenez que notre console ne supporte pas le caractère \u0153 ? (C'est pour cela qu'on a utilisé repr().)
Donc, encodons la chaîne dans un charset supporté par notre console:
>>> import sys
>>> file=open('monfichier.txt','r')
>>> print file.read().decode('utf-8').encode(sys.stdout.encoding,'replace')
?uvre
>>>
Oui, ça a l'air lourd, c'est vrai.
Mais n'oubliez pas qu'on est en train de convertir entre 3 modes : UTF-8 (le fichier texte en entrée), Unicode (la chaîne Python) et cp437 (le charset de notre console).
| UTF-8 |
→ |
Unicode |
→ |
cp437 |
| Le fichier en entrée. |
.decode('utf-8')
|
Chaîne Python. |
.encode('cp437') |
La console en sortie. |
C'est pour cela que nous devons explicitement convertir entre ces différents encodages.
Explicite est mieux qu'implicite.
Liens complémentaires (articles en anglais):
Dernière mise à jour: 2006-08-02