
|
C'est quoi l'ASCII, l'UNICODE, l'UTF-8 ? |
L'ordinateur est une grosse machine à calculer : tout ce qu'il sait faire, c'est effectuer des calculs sur des nombres. Il est incapable de comprendre le texte.
Il faut donc faire un choix : par quel nombre on prend pour représenter la lettre 'A' ? Et pour les signes de ponctuation, quels nombres utiliser ?
Il existe différentes conventions (ou codes). L'un des plus connus est le code ASCII (American Standard Code for Information Interchange). C'est un standard américain, mais c'est l'un des plus utilisés, en particulier sur la plupart des ordinateurs.
Le code ASCII définit précisément la correspondance entre symboles et nombres jusqu'au nombre 127:
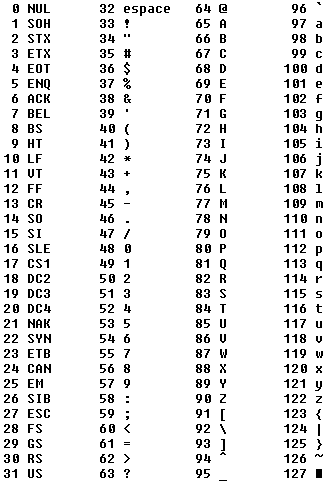
Il faut donc utiliser le nombre 97 pour représenter un 'a' minuscule. Pour représenter un '?', il faut utiliser le code 63.
Certains codes (ceux inférieurs à 32) sont des codes de contrôle (il ne sont pas faits pour être affichés). Par exemple le code 10 permet d'aller à la ligne, le code 7 fait biper l'ordinateur, etc.
Mais vous avez remarqué ? Il n'y a aucun caractère accentué ! Les américains nous ont oublié. Nous et d'autres pays : l'Espagne (avec le point d'interrogation retourné par exemple), l'Allemagne, etc. Sans parler des pays comme la chine ou le japon avec leurs différents alphabet...
Il nous arrive souvent d'utiliser les codes de 128 à 255 pour les accents, mais ces codes sont différents d'un pays à l'autre ! Pas pratique pour échanger des documents.
Il faut donc trouver un code plus pratique. Il existe: c'est l'UNICODE.
Le code UNICODE permet de représenter tous les caractères spécifiques aux différentes langues. De nouveaux codes sont régulièrement attribués pour de nouveaux caractères: caractères latins (accentués ou non), grecs, cyrillics, arméniens, hébreux, thaï, hiragana, katakana... L'alphabet Chinois Kanji comporte à lui seul 6879 caractères.
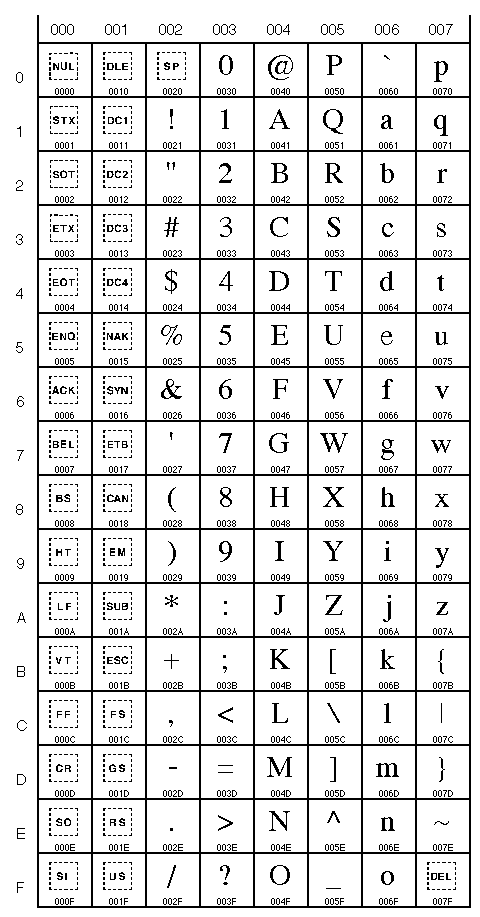
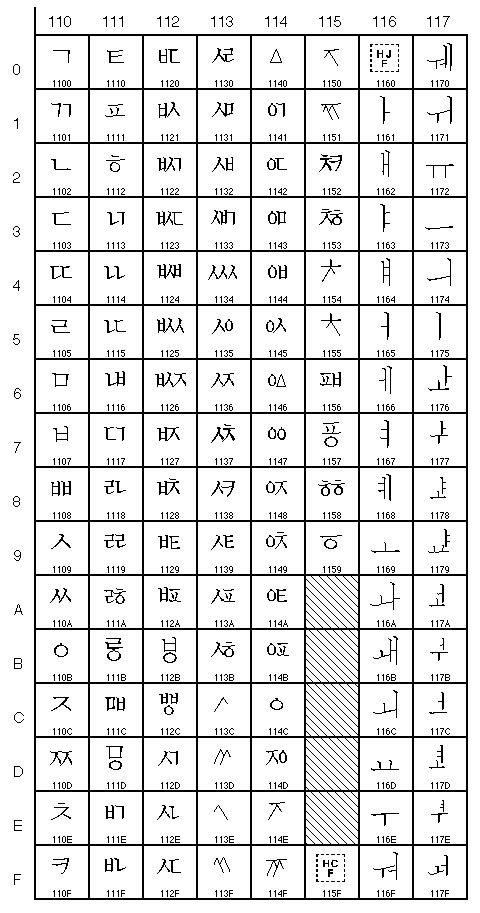
L'Unicode définie donc un correspondance entre symboles et nombres.Voici une toute petite partie des tables UNICODE (les nombres sont présentés en notation hexadécimal):
 |
 |
 |
 |
| Caractères Unicode 0000 à 007F (0 à 127) (caractères latins) |
Caractères Unicode 0080 à 00FF (128 à 255) (caractères latins, dont accentués) |
Caractères Unicode 0900 à 097F (2304 à 2431) (caractères devanagari) |
Caractères Unicode 1100 à 117F (4352 à 4479) (caractères hangul jamo) |
Vous pourrez trouver plus d'informations sur l'UNICODE sur http://www.unicode.org.
Même si l'UNICODE est bien conçu, il reste assez peu utilisé par rapport à l'ASCII. (Ne vous amusez pas à envoyer un message en UNICODE à quelqu'un : il ne saurait probablement pas comment le lire !). Pour les programmeurs, ça n'est pas toujours très facile à manipuler non plus.
Ce standard se développe de plus en plus. Les langages Java, .Net (C#) et Python supportent déjà nativement l'UNICODE. La plupart des systèmes d'exploitation (Windows, Linux, MacOS X...) supportent déjà l'Unicode.
Bon. Unicode, dans la théorie, c'est très bien.
Mais dans la pratique, c'est une autre paire de manches:
Généralement en Unicode, un caractères prend 2 octets. Autrement dit, le moindre texte prend deux fois plus de place qu'en ASCII. C'est du gaspillage.
De plus, si on prend un texte en français, la grande majorité des caractères utilisent seulement le code ASCII. Seuls quelques rares caractères nécessitent l'Unicode.
On a donc trouvé une astuce: l'UTF-8.
Un texte en UTF-8 est simple: il est partout en ASCII, et dès qu'on a besoin d'un caractère appartenant à l'Unicode, on utilise un caractère spécial signalant "attention, le caractère suivant est en Unicode".
Par exemple, pour le texte "Bienvenue chez Sébastien !", seul le "é" ne fait pas partie du code ASCII. On écrit donc en UTF-8:
![]()
Pour être rigoureux, on indique quand même au début du fichier que c'est un fichier en UTF-8 à l'aide de caractères spéciaux:
![]()
Et voilà !
L'UTF-8 rassemble le meilleur de deux mondes: l'efficacité de l'ASCII et l'étendue de l'Unicode. D'ailleurs l'UTF-8 a été adopté comme norme pour l'encodage des fichiers XML. La plupart des navigateurs récents supportent également l'UTF-8 et le détectent automatiquement dans les pages HTML.
Si vous mettez directement le caractère "é" dans une page web, ce n'est pas bien. ll faut obligatoirement choisir une des 3 solutions suivantes:
é à la place de "é".é" tel quel et préciser le charset que vous utilisez au début du fichier HTML (dans la balise <head>):<meta http-equiv="Content-type" content="text/html; charset=ISO-8859-1"><meta http-equiv="Content-type" content="text/html; charset=UTF-8">| Le contenu de cette page est placé sous les termes de la licence suivante : CC Attribution-Noncommercial 4.0 International |
| h t t p : / / s e b s a u v a g e . n e t |