NVIDIA: Contact With Anna’s Archive Doesn’t Prove Copyright Infringement
![]() Last month, we reported on an expanded class-action lawsuit in which several authors accused NVIDIA of using millions of pirated books to train its AI models.
Last month, we reported on an expanded class-action lawsuit in which several authors accused NVIDIA of using millions of pirated books to train its AI models.
The complaint cited internal emails showing that NVIDIA contacted Anna’s Archive seeking “high-speed access” to the shadow library’s massive collection. After being warned about the illegal nature of the materials, NVIDIA executives allegedly gave the “green light” to proceed.
Now, NVIDIA has fired back with a comprehensive motion to dismiss, calling the authors’ allegations speculative, vague, and legally insufficient.
Contact With ‘Anna’ Isn’t Enough
At the California federal court, NVIDIA argues that the authors’ complaint is built on speculation rather than facts.
While the complaint shows evidence suggesting that NVIDIA contacted Anna’s Archive about potentially accessing “millions of pirated materials,” NVIDIA points out a crucial gap: the authors never actually allege that NVIDIA downloaded their specific books from the shadow library.
“The only plausible facts alleged about Anna’s Archive are that NVIDIA ‘contacted Anna’s Archive’ about unspecified data, Anna’s Archive asked NVIDIA to confirm, and
NVIDIA gave the “green light” to ‘proceed’.”
“The mere fact that NVIDIA was in contact with representatives from Anna’s Archive does not mean that NVIDIA obtained Plaintiffs’ works from Anna’s Archive. It’s equally plausible NVIDIA did not,” the motion states.

The chip giant notes that the authors rely heavily on allegations made “upon information and belief”. This is a legal phrase that essentially means that it is an educated guess, rather than a statement that can be backed up with evidence.
Anna’s Archive ‘Backs’ NVIDIA
It’s worth noting that after our original coverage, AnnaArchivist weighed in on Reddit, stating they have not been in direct contact, suggesting the company may have used an intermediary.
“We’ve never dealt with Nvidia directly, so they likely used an intermediate party to avoid legal issues. But if Nvidia were to contact us directly, we’d happily provide them with high speed access in exchange for a donation,” the site’s representative wrote.
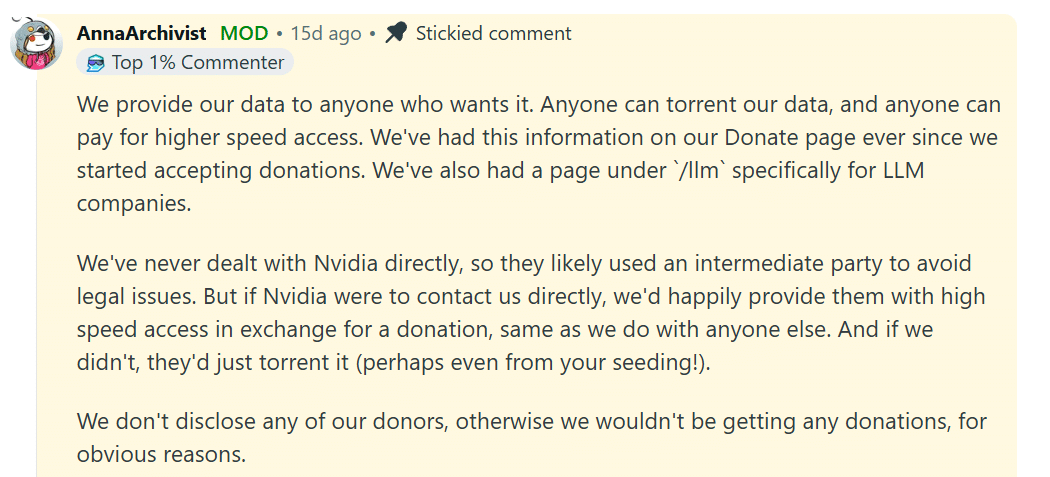
Whether this clarification helps or hurts the authors’ case remains to be seen. In any case, NVIDIA does not mention it in its motion to dismiss.
Catch-All Fishing Expedition
Aside from the Anna’s Archive rebuttal, NVIDIA describes the amended complaint as a fishing expedition that includes “improper catch-all allegations” that target virtually every AI model and dataset the company has ever worked with.
The original complaint focused narrowly on the NeMo Megatron model family and the Books3 dataset. But the amended version now references unidentified “NVIDIA LLMs,” unnamed “internal models,” undefined “NextLargeLLM” models, and unspecified “other shadow libraries.”
Shortly after filing their updated complaint, the authors sent new discovery requests targeting these new models and datasets.
“Plaintiffs’ bid for limitless discovery is confirmed by the blizzard of discovery requests they served after filing,” NVIDIA writes, as further evidence for the alleged fishing expedition.
No Proof Books Were Actually Used
In addition to Anna’s Archive, the amended complaint also adds various other shadow libraries, including Bibliotik, LibGen, Sci-Hub, Z-Library, and Pirate Library Mirror.
However, according to NVIDIA, the complaint lacks proof that the company downloaded the authors’ books. Similarly, it argued that there is no evidence that specific books or datasets were used to train LLMs.
For example, for the Nemotron-4 models, the authors simply speculated that because the training dataset was large and contained books, it must have included their works. NVIDIA dismissed this line of reasoning, noting that speculation is not enough.
“[T]he absence of factual allegations that the data used to train Nemotron-4 15B and Nemotron-4 340B included Plaintiffs’ works requires dismissal as to those models,” the motion to dismiss reads.
Secondary Infringement Claims Fail
The amended complaint added two new legal theories: contributory and vicarious copyright infringement. Both claims allege that NVIDIA helped customers infringe by providing tools to download ‘The Pile’ dataset.
NVIDIA argues these claims fail from the start. Both require an underlying act of direct infringement by a third party, but the authors only speculate “on information and belief” that NVIDIA’s customers downloaded and used The Pile.
The complaint names three purported NVIDIA customers but “does not identify any customer alleged to have downloaded or used The Pile,” the motion states.
Even if third-party infringement occurred, NVIDIA argues the authors fail to show the company had knowledge of specific infringing acts or materially contributed to them. The NeMo framework provides optional tools that customers can choose to use with any dataset—including licensed or public domain materials.
“The NeMo framework is capable of substantial non-infringing uses,” NVIDIA writes, citing legal precedent that bars liability when products have legitimate purposes.
NVIDIA Requests Dismissal
All in all, NVIDIA wants the court to dismiss all the expanded claims, including the addition of the new models, the new shadow libraries, and the alleged communication with Anna’s Archive.
The company further argues that the contributory and vicarious copyright infringement claims should be dismissed completely, as there is no evidence that specific books were pirated.

Notably, the direct copyright infringement claim, which alleges that NVIDIA used the Books3 database to train its NeMo model, is not covered by the motion. NVIDIA plans to defeat that during trial or on summary judgment, likely through a defense that relies heavily on fair use.
—
A copy of NVIDIA’s motion to dismiss is available here (pdf). It is scheduled for a hearing on April 2, 2026, before Judge Jon S. Tigar in Oakland, California.
From: TF, for the latest news on copyright battles, piracy and more.











")



