Table des matières
Recherche floue
Dans différentes applications on a besoin d'effectuer des recherches. Il peut parfois être utile de retourner des résultats dont l'orthographe ou la phonétique sont proches (par exemple, retourner "wikipedia" pour "wikipdia", ou "sceau" pour "sot").
Il existe différentes méthodes. La plus utilisée combine un encodage phonétique (soundex ou autres) et un calcul de distance (Levenshtein).
Calcul de distance (Levenshtein/Hamming)
Cette méthode consiste à calculer la distance entre deux mots.
- Chaque fois qu'une lettre est substituée, on ajoute 1.
- Chaque fois qu'une lettre est supprimée, on ajoute 1.
- Chaque fois qu'une lettre est ajoutée, on ajoute 1.
php est fourni en standard avec cette fonction. Exemple:
<?php header('content-type: text/plain'); function distance($a,$b) { echo $a.'->'.$b.' : '.levenshtein($a,$b)."\n"; } distance('wikipedia','wikipedia'); distance('wikepedia','wikipedia'); distance('wikepdia','wikipedia'); ?>
Ce qui donne ceci:
wikipedia->wikipedia : 0 wikepedia->wikipedia : 1 wikepdia->wikipedia : 2
Attention: Cette fonction est sensible à la casse. Ainsi la distance entre 'wikipedia' et 'WIKIPEDIA' est de 9. Il convient donc de tout passer en minuscules avant de calculer la distance:
levenshtein(strtolower($a),strtolower($b));
Toutefois, levenshtein ne règle pas le problème des mots ayant la même sonorité mais avec une orthographe différente. Il convient alors d'encoder phonétiquement les mots.
Encodage phonétique
Il existe différentes méthodes. Elles ont toutes leurs contraintes:
- Support plus ou moins bon des particularités des différentes langues.
- Implémentations supportant ou non l'UTF-8.
- Consommation CPU.
Liste non exhaustive:
- Soundex. Problème: Cet algo est surtout adapté à l'anglais, et il est limité à 4 caractères. Il existe des versions dérivées mieux adaptées au français:
- Phonétique par Édouard BERGÉ.
- Soundex Français par Florent Bruneau.
- autre version d'un soundex adapté au français.
- Double-metaphone, qui est limité à 4 caractères, mais qui est censé être adapté à d'autres langues que l'anglais (langues slaves, germaniques, grec, français, Italien, espagnol, chinois et autres). Particularité: Il renvoie deux racines par mot, ce qui permet de faire des rapprochements. (voir l'implémentation php de Stephen Woodbridge).
Voici quelques exemples d'encodages phonétiques:
| Mot | soundex | soundex_fr (Florent Bruneau) | Phonetique (Édouard BERGÉ) | metaphone | doubleMetaphone (primary) | doubleMetaphone (secondary) |
|---|---|---|---|---|---|---|
| sceau | S000 | SO | SO | S | S | S |
| seau | S000 | SO | SO | S | S | S |
| sot | S300 | SO | SO | ST | ST | ST |
| saut | S300 | SO | SO | ST | ST | ST |
| wikipedia | W213 | VKPD | OUIKIPEDIA | WKPT | AKPT | FKPT |
| éléphant | L153 | ELF | ELEFAN | LFNT | LFNT | LFNT |
| anticonstitutionnellement | A532 | ATKO | ANTIKONSTITUSION | ANTKNSTTXNLMNT | ANTK | ANTK |
| athmosphérique | A352 | AT0F | ATMOSFERIK | A0MSFRK | A0MS | ATMS |
| comportement | C516 | KOPO | KONPORTEMAN | KMPRTMNT | KMPR | KMPR |
Il devient alors intéressant de calculer la distance levenshtein sur ces codes.
On voit clairement que les algos adaptés aux français donnent de meilleurs résultats. Les autres bottent en touche, généralement, en supprimant les voyelles (accentuées ou non), ce qui leur donne un taux de réussite correcte malgré tout (même si, comme on le voit, elles ne gèrent pas les consonnes sourdes, comme le "t" dans le mot "sot").
Notez que (heureusement), ces algos ignorent les différences minuscules/majuscules.
Combinaison
Ce qui est généralement pratiqué pour la recherche floue:
- Encodage des mots à comparer en phonétique.
- Calcul de la distance de levenshtein entre les mots, ramené à la longueur du mot (exemple: distance 2 sur un mot de 7 lettres –> 2/7*100 = 28,5% de différence)
- On ne renvoie que les mots qui ont moins de X% de différence.
$phon1 = soundex_fr($mot1); $phon2 = soundex_fr($mot2); $pourcentage = levenshtein($phon1,$phon2)*100/strlen($mot1); if ($pourcentage<=25) echo $mot2.' est proche de '.$mot1
Le seuil est à choisir en fonction:
- De la précision de l'algo choisi par rapport à la langue.
- Du nombre de suggestions que vous voulez ramener à l'utilisateur.
- De votre corpus (distribution des mots variée ou non, mélange de langues, quantité de données…)
Exemple
Petit exemple de recherche floue. Ce que fait ce programme d'exemple:
- Il charge en mémoire un dictionnaire français limité de 22740 mots.
- Il compare le mot entré à ce dictionnaire avec la distance de levenshtein en encodant avec l'algo sélectionné (soundex,metaphone,soundex_fr ou phonétique)
- Il renvoie les mots ayant au plus 5% de différence avec le mot entré.
Voici le source ( Ce script n'est pas sûr - à ne pas exécuter en environnement de production.):
Ce script n'est pas sûr - à ne pas exécuter en environnement de production.):
Et pour que cela soit plus simple: voici le fichier zip: test_phonetique.zip
Exemple d'utilisation:
En cherchant le mot "raté" avec Soundex:
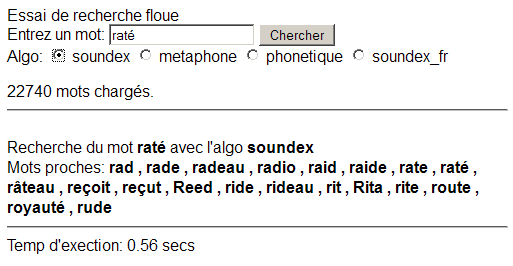
Avec metaphone:

Avec soundex_fr:

Avec Phonétique:

Comme on peut le constater:
- soundex ne gère pas les accents, donnant d'assez mauvais résultats.
- metaphone, qui n'est pas non plus adapté au français, ne fait guère mieux.
- soundex_fr est déjà nettement plus pertinent, mais étant limité (comme soundex) à 4 phonèmes, il remonte également plein de mots inutiles (restants, restées…)
- phonétique est très pertinent (fidèle à la phonétique du mot d'origine), et n'étant pas limité à 4 phonèmes, il ne renvoie pas de mots inutiles. Mais il a un temps de traitement important (plus de 30 secondes là où soundex_fr prend environ 3 secondes).
Le choix de l'algo est un compromis entre la qualité des résultats et la charge CPU. Notez que:
- On peut réduire (voir annuler) la charge CPU en pré-calculant les phonèmes.
- On peut choisir d'utiliser un algo moins précis (comme soundex_fr) mais en limitant le nombre de résultats retournés (par exemple 8 maximum) pour éviter de noyer l'utilisateur dans des suggestions inutiles.
A voir
A prendre en considération (non traité ici)
- Quand déclencher la recherche floue (uniquement en cas d'échec de la comparaison brute ?)
- Support UTF-8
- comportement avec des langues mélangées dans un même texte.