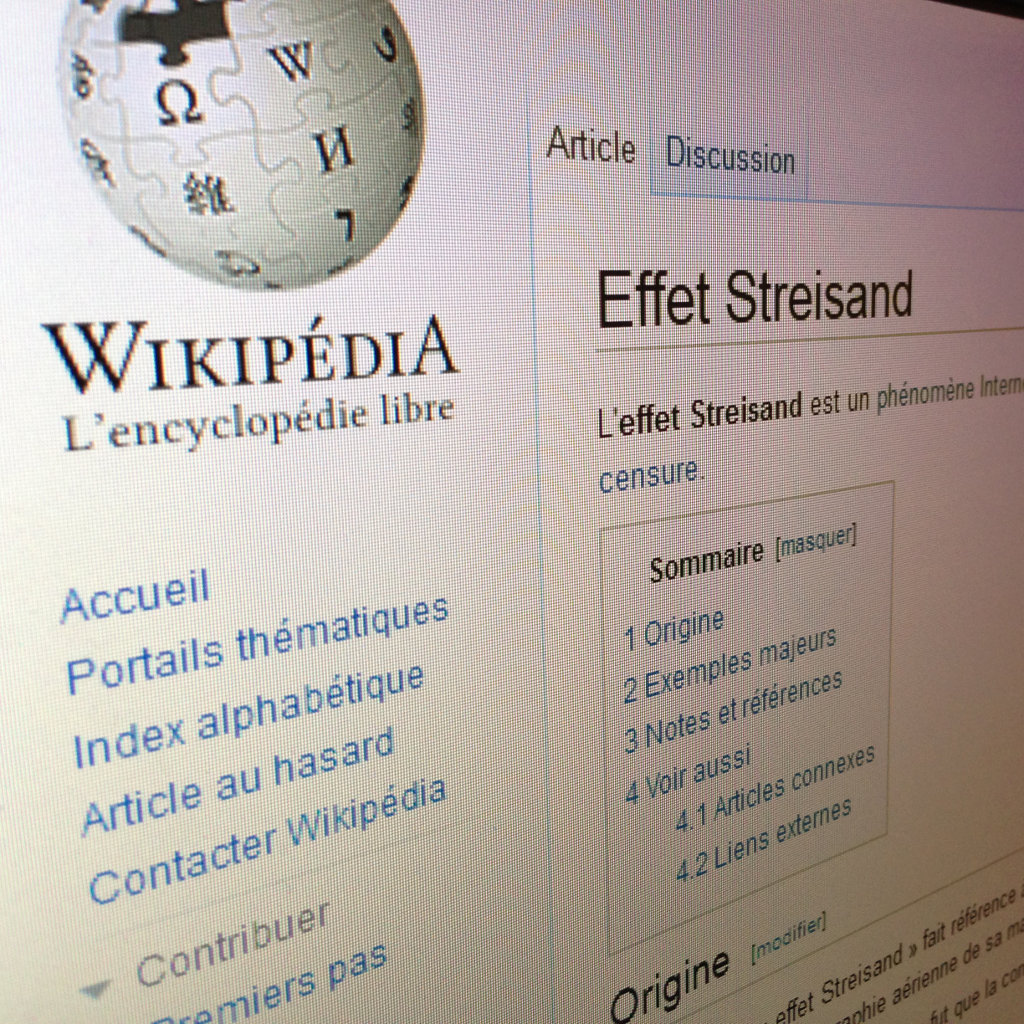
Page Wikipédia sur l’effet Streisand
Le 4 mars 2013, la Direction centrale du renseignement intérieur (DCRI) contacte la Wikimedia Foundation pour exiger la censure immédiate d’un article sur sa célèbre encyclopédie en ligne Wikipédia.
L’article en question porte sur la station hertzienne militaire de Pierre-sur-Haute, un article qui date pourtant de juillet 2009. Presque 2 ans et demi pour réagir, wow !
Faute d’explications, la Wikimédia Foundation ne voit pas en quoi les informations pourraient porter atteinte au secret de la défense nationale. Outre-Atlantique, la fondation refuse donc de se plier aux exigences de la DCRI, considérant à la vue des informations fournies, rien ne permettait de déterminer le caractère litigieux de l’article incriminé.
Tout s’accélère le 4 avril 2013, lorsque la DCRI convoque Rémi Mathis, bénévole à l’association de soutien Wikimédia France, pour lui ordonner de supprimer l’article. Selon la Fondation, ce bénévole a été visé par la DCRI uniquement parce qu’il était facilement identifiable, de par ses actions régulières de promotion de Wikipédia et des projets Wikimedia en France. Sous la menace d’une garde à vue et de poursuites judiciaires pouvant aller jusque 5 ans de prison et 75 000 euros d’amende, Rémi Mathis est contraint d’obtempérer et de supprimer l’article dans les locaux de la DCRI. Au moment de la suppression, il prévient d’autres administrateurs.
En l’espace de quelques heures, la page que la DCRI souhaitait censurer a été remise en ligne et est devenue la plus consultée sur la version France de Wikipedia, plus encore que la page de Jérôme Cahuzac et a été traduite dans d’autres langues (13 traductions à l’heure actuelle).

Fréquentation de Wikipédia France au cours des dernières heures
La Wikimedia Foundation s’explique :
- Position de la Fondation :
« Quand les gouvernements ont des soucis de sécurité sur les articles Wikipédia, ils devraient diriger directement leurs requêtes à la Fondation, et ‘’seulement‘’ à la Fondation. Nous pensons qu’il est inutile, irresponsable et souvent contre-productif pour toute agence gouvernementale de contacter directement les utilisateurs ou les volontaires de tout site Wikimedia pour résoudre les problèmes et devraient travailler en étroite collaboration avec la Fondation. Dans le passé, nous avons travaillé avec un certain nombre d’agences de par le monde pour résoudre leurs problèmes de façon consistante avec les besoins de l’agence et les principes de la communauté.
Alors que nous n’avions jamais reçu de requête de cette nature de la DCRI auparavant, il y a malheureusement déjà eu des entités gouvernementales qui ont contacté, voire même harcelé, des utilisateurs locaux. La Fondation s’oppose fermement à toute tentative d’intimidation gouvernementale envers les volontaires qui consacrent leur temps et leur énergie à construire une des plus grandes ressources éducationnelles du monde que chacun peut librement réutiliser. Nous nous attristons et sommes déçus de découvrir que la DCRI pense que la tactique qu’ils emploient au nom de la sécurité dans ce domaine peut être acceptable d’un point de vue juridique ou moral. La Fondation voulait, et continue à vouloir, travailler avec la DCRI pour résoudre cette affaire si possible, mais nous ne tolérons en aucun cas le harcèlement d’individus qui n’ont rien fait de mal.
La Fondation est bien entendu sensible aux soucis de sécurité nationale, mais dans les cas où il n’y a pas de menace ‘’apparente‘’ mais juste une vague demande non justifiée de menace de sécurité nationale, nous avons besoin de plus d’information avant d’envisager de retirer du contenu — faire autrement serait autoriser la censure pour limiter la libre expression, ce qui serait un assaut direct sur les valeurs de la communauté Wikimedia. Tous les cas sont examinés et évalués au cas par cas, et certains sont résolus plus facilement que d’autres. Dans ce cas, nous n’avons pas été en mesure de réellement déterminer que l’information était classifiée telle qu’elle est et — en particulier à la lumière de la vidéo — pensons que notre requête adressée à la DCRI pour plus d’informations est raisonnable.
La communauté reste libre, bien sûr, de conserver ou retirer l’article puisqu’il semble répondre aux politiques et processus de la communauté. Nous apprécions et respectons les décisions de la communauté à cet égard. Cependant, nous voulons rappeler aux utilisateurs qui sont sujets à la juridiction de la France qu’il y a des risques à poster du contenu que les autorités gouvernementales ne veulent pas voir posté, et nous conseillons à ces utilisateurs de consulter un conseil juridique avant d’agir dans une situation qui semble potentiellement risquée. En l’état, nous ne voyons pas de raison valable de retirer l’article sur des bases légales. »
La fondation Wikimédia ne comprend pas et n’admet pas que l’on utilise l’intimidation et des méthodes expéditives contre un bénévole œuvrant pour un accès libre et gratuit à la connaissance pour le plus grand nombre, elle s’en explique dans ce communiqué de presse.
Si vous souhaitez en savoir plus, Wikipédia a ouvert une revue de presse dédiée.
La Wikimédia Foundation rappel qu’elle a suspendu les droits d’administration du bénévole, ainsi que de trois autres administrateurs, pour les préserver si jamais la DCRI voulait encore se prêter au jeu de l’intimidation.
On résume rapidement :
– La DCRI s’agite plus de 2 ans après la publication, et tente de censurer un article complet en urgence, sans explications et sans documents légaux.
– La Wikimedia Foundation refuse de censurer l’article au motif que la demande de la DCRI ne présente pas de motivations suffisantes pour justifier un retrait.
– La DCRI s’attaque alors directement à un contributeur bénévole de Wikimédia France, une association qui vise à soutenir et promouvoir les projets Wikimédia, dont Wikipédia fait partie. Wikimédia France n’est en aucun cas éditeur ou hébergeur de Wikipédia.
– Ce qui est choquant n’est pas la demande de retrait en soit, c’est la forme. Utiliser la ruse et l’intimidation sur un bénévole pour parvenir à ses fins, « juste parce qu’il avait des droits d’administration ». La France, pays des droits de l’homme est, et doit rester un État de droit !
– L’article incriminé contenait des informations connues, documentées par le biais de liens en bas de page, d’autant plus que le web regorge d’informations sur cette base, y compris par des reportages vidéo.
– La DCRI démontre sa méconnaissance d’internet et récolte ce qu’elle sème avec un magnifique effet streisand. EPIC FAIL !









 )… J’ai comme l’impression qu’OVH délaisse de plus en plus ses clients « low-cost » et que la concurrence mérite d’être encouragée pour ce marché de niche qui n’en est plus vraiment un !
)… J’ai comme l’impression qu’OVH délaisse de plus en plus ses clients « low-cost » et que la concurrence mérite d’être encouragée pour ce marché de niche qui n’en est plus vraiment un !