fortunes-fr
Sous Linux, fortunes est un petit programme en ligne de commande qui affiche des citations. On s'en sert souvent pour en afficher quand on ouvre un nouveau terminal, ou encore en économiseur d'écran (l'économiseur d'écran Phosphor dans xscreensaver).
Pour l'installer:
sudo apt install fortune-mod
Par défaut, les citations sont anglophones. On peut en installer en français:
sudo apt install fortunes-fr
Pour lancer le programme, tapez simplement:
fortune
On peut aussi supprimer les anglophones:
sudo apt remove fortunes-min
sudo rm /usr/share/games/fortunes/*.dat
Mais le fichier de fortunes francophone a été mis à jour pour la dernière fois en 2004. C'est dommage.
J'ai décider de scraper le site citation-celebre.com pour construire un nouveau fichier de fortunes.
Nouvelle citations
Voici donc un nouveau fichier de fortunes contenant plus de 80 000 citations en français issues du site web citation-celebre.com.
Installation
-
Virez les citations existantes si vous le souhaitez: sudo rm -rf /usr/share/games/fortunes/*
Copiez ces nouvelles citations: sudo cp citation-celebre.com* /usr/share/games/fortunes
Et voilà, vous pouvez profiter des citations: fortune
Le programme
Vous pouvez lancer le programme suivant pour scraper vous-même les citations sur le site, mais je vous demande, si c'est possible, d'éviter. De préférence, utilisez le fichier de citation que j'ai déjà créé. Cela évitera de charger inutilement le site web.
Cliquez pour afficher le programme
Cliquez pour afficher le programme
- scraper-citation-celebre.py
#!/usr/bin/python
# coding: utf-8
'''
scraper-citation-celebre.py
Version 2019-11-07
Récupère des citations de http://www.citation-celebre.com/liste-citation
et créé un fichier compilable par fortunes (sous Linux)
Une fois ce script terminé, faire: strfile citation-celebre.com
Cela va créer le fichier citation-celebre.com.dat
et copier les deux fichiers : sudo cp citation-celebre.com* /usr/share/games/fortunes
Ce script est interruptible à tout moment. Vous pouvez l'arrêter et le relancer:
Il reprendra là où il en était.
'''
import lxml.html,requests,codecs,sys,UserDict,os,os.path
from sqlite3 import dbapi2 as sqlite
class dbdict(UserDict.DictMixin):
''' dbdict, a dictionnary-like object for large datasets (several Tera-bytes) '''
def __init__(self,dictName):
self.db_filename = "dbdict_%s.sqlite" % dictName
if not os.path.isfile(self.db_filename):
self.con = sqlite.connect(self.db_filename)
self.con.execute("create table data (key PRIMARY KEY,value)")
else:
self.con = sqlite.connect(self.db_filename)
def __getitem__(self, key):
row = self.con.execute("select value from data where key=?",(key,)).fetchone()
if not row: raise KeyError
return row[0]
def __setitem__(self, key, item):
if self.con.execute("select key from data where key=?",(key,)).fetchone():
self.con.execute("update data set value=? where key=?",(item,key))
else:
self.con.execute("insert into data (key,value) values (?,?)",(key, item))
self.con.commit()
def __delitem__(self, key):
if self.con.execute("select key from data where key=?",(key,)).fetchone():
self.con.execute("delete from data where key=?",(key,))
self.con.commit()
else:
raise KeyError
def keys(self):
return [row[0] for row in self.con.execute("select key from data").fetchall()]
pagecache = dbdict('pages-citations')
file = codecs.open("citation-celebre.com", "w", "utf-8")
npage = 1
def cleanString(s):
return s.replace("\t",' ').replace("\r\n",' ').replace("\r",' ').replace("\n",' ').replace(' ',' ')
while npage < 8069:
url = u'http://www.citation-celebre.com/liste-citation?page=%d' % npage
if url not in pagecache:
sys.stderr.write("Récupération page %d... \n" % npage)
page = requests.get(url)
pagecache[url]=page.content.decode('utf-8')
pagedata = pagecache[url]
tree = lxml.html.fromstring(pagedata)
citations = tree.xpath('//div[@class="citation"]')
for citation in citations:
# Extraction des citations de la page:
texte = citation.xpath('.//p[@class="laCitation"]/q/a')[0].text_content().strip()
auteur = "" # Attention l'auteur peut être vide.
auteurElement = citation.xpath('.//div[@class="auteur"]//div[@class="additionalInformation"]//a[@class="auteurLien"]')
if auteurElement :
auteur = cleanString(auteurElement[0].text_content().strip())
# Écriture dans le fichier.
if u"► Lire la suite" in texte:
continue # On zappe les citations trop longues.
file.write("%s\n" % texte)
if len(auteur)>0: file.write(" -- %s\n" % auteur)
file.write("%\n")
npage += 1
file.close()
Voir aussi: https://sebsauvage.net/links/?gKjK1A
Une citation chaque fois que vous ouvrez un terminal
Ajoutez à la fin de votre fichier ~/.bashrc:
fortune
Ou pour faire plus coloré, après un sudo apt intall lolcat, ajoutez:
fortune | lolcat
Et du coup, chaque fois que vous ouvrez un terminal, vous avez droit à une petite citation colorée:
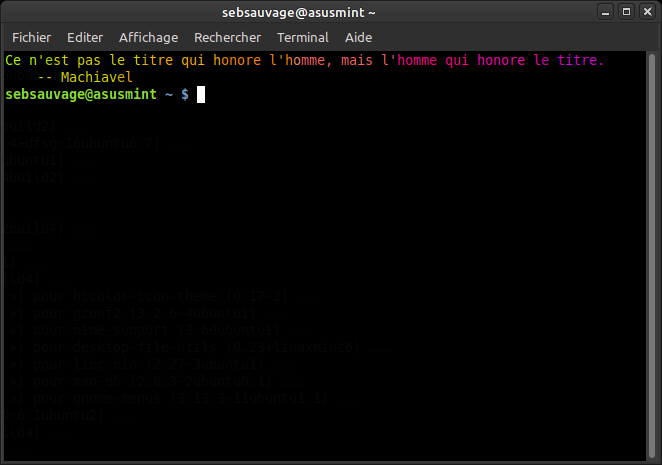
ou éventuellement un
fortune | cowsay
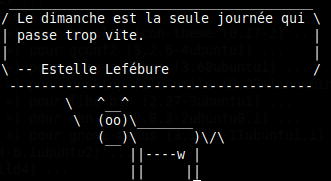
ou si vous voulez quelque chose d'encore plus voyant:
fortune | toilet -f pagga.tlf -t | lolcat

Source potentielles (à explorer/aspirer)